Exploration von Empfehlungsdiensten - Klasse 8 bis 10
Hinweis: Dieses Unterrichtsmodul befindet sich noch in der Erprobungsphase und wird von uns noch evaluiert sowie überarbeitet. Bei Interesse an Erprobungen melden Sie sich gerne bei Lukas Höper aus der Didaktik der Informatik.
{{#if:Datei:ProDaBi Logo.png|
}}
{{#if:Datenbewusstsein| }} {{#if:Lukas Höper| }} {{#if:| {{#if:| | }} }} {{#if:| {{#if:| | }} }} {{#if:| {{#if:| | }} }} {{#if:| {{#if:| | }} }} {{#if:| {{#if:| | }} }} {{#if:| }}| Themenfeld | Datenbewusstsein |
|---|---|
| Autor | Lukas Höper |
| Editiert am | 02.4.2023 |
| Material | [[:|]] |
| Material | [[:|]] |
| [[:|]] | |
| [[:|]] | |
| [[:|]] | |
| [[:|]] | |
| [[:{{{Material3}}}|{{{Material3_Name}}}]] | |
| [[:{{{Material3}}}|{{{Material3}}}]] | |
| [[:{{{Material4}}}|{{{Material4_Name}}}]] | |
| [[:{{{Material4}}}|{{{Material4}}}]] | |
| Unterseiten |
Daten spielen im alltäglichen Leben in der digitalen Welt uns bewusst oder auch unbewusst eine große Rolle. Schülerinnen und Schüler interagieren tagtäglich mit verschiedenen datengetriebenen digitalen Artefakten (z.B. der News Feed auf einer Social Media Plattform oder die Startseite bei etwa Netflix oder Spotify). In diesem Unterrichtsmodul werden Empfehlungsdienste (engl. Recommender Systems) als Beispiel für datengetriebene digitale Artefakte thematisiert, bei deren Nutzung verschiedene Daten explizit und implizit erhoben und generiert werden, wie etwa Bewertungsdaten der Nutzerinnen und Nutzer. Konkret wird dazu exemplarisch ein Filmempfehlungsdienst im Kontext von Streamingdiensten aufgegriffen. Anhand dieses Beispiels soll in diesem Unterrichtsmodul eine Förderung des Datenbewusstseins der Schülerinnen und Schüler stattfinden, wozu die Leitfrage „Wo, wie und wozu werden Daten gesammelt und verarbeitet?“ beispielhaft beantwortet wird.
Steckbrief des Unterrichtsmoduls
Titel: Wo, wie und wozu werden Daten gesammelt und verarbeitet? – Datenbewusstsein durch die Exploration von Empfehlungsdiensten im Kontext von Streamingdiensten
Stichworte: Datenbewusstsein, Data Science, Exploration von Empfehlungsdiensten
Zielgruppe: Informatik in Klasse 8 bis 10 (alle Schulformen)
Inhaltsfeld: "Informatik, Mensch und Gesellschaft" (Schwerpunkt: Datenbewusstsein), "Information und Daten", "Informatiksysteme" und "Künstliche Intelligenz und maschinelles Lernen"
Vorkenntnisse: Dieses Unterrichtsmodul setzt keine besonderen Vorkenntnisse der Lernenden voraus. Es sollte jedoch eine grundlegende Erfahrung im Umgang mit dem Computer vorhanden sein. Außerdem sind grundlegende Vorstellungen des Datenbegriffs wünschenswert, entsprechende Einführungen könnten aber auch in diesem Modul integriert werden. Ein Verständnis von Künstlicher Intelligenz oder Maschinellem Lernen ist nicht nötig, im Gegenteil werden in diesem Modul Aspekte dessen bereits aufgegriffen – diese könnten auch in einer Adaption des Unterrichtsmoduls erweitert werden.
Zeitlicher Umfang: 6-8 Unterrichtsstunden a 45 Minuten
Überblick über den Verlauf des Unterrichtsmoduls
Dieses Unterrichtsmodul vermittelt Datenbewusstsein: Die Kompetenz, sich die Rolle der erhobenen und verarbeiten Daten bei der Nutzung unterschiedlicher Anwendungen bewusst zu werden, um schließlich die Nutzung bewerten und eigene Handlungsoptionen identifizieren zu können. Damit wird das Ziel verfolgt, die Lernenden zu einer selbstbestimmten Interaktion mit datengetriebenen Anwendungen in ihrem Alltag zu befähigen. Das Modul setzt sich aus vier Teilen zusammen und thematisiert exemplarisch die Erhebung und Verarbeitung von persönlichen Daten bei der Nutzung von Streamingdiensten, bei denen Empfehlungsdienste eingesetzt werden. Fokussiert wird die Rolle der Daten für einen Empfehlungsdienst, wie etwa bei der Startseite bei einem Streamingdienst zu erkennen, wobei ebenfalls weiterführend auch andere Alltagskontexte der Lernenden aufgegriffen werden.
Im ersten Teil wird in Empfehlungsdienste als Kontext und in die Idee der personalisierten Filmempfehlungen eingeführt. Dabei wird erarbeitet, welche persönlichen Daten bei der Nutzung eines exemplarischen Streamingdienstes, insbesondere für den primären Zweck des Gebens von personalisierten Filmempfehlungen, erhoben werden. Zum Beispiel sind dafür Nutzungsdaten interessiert, wie etwa welche Filme ein Nutzender zuvor geschaut hat. Dabei entwickeln die Lernenden bereits erste Ideen, was es bedeutet, einem Nutzenden Empfehlungen anzuzeigen und wie solche Filmempfehlungen ermittelt werden könnten.
Im zweiten Teil wird die Funktionsweise eines Filmempfehlungsdienstes rekonstruiert, wofür die Lernenden in einer vorbereiteten Lernumgebung mit einem funktionierenden Filmempfehlungsdienst (basierend auf realen Nutzungsdaten aus dem Streamingkontext) interagieren und schrittweise die Funktionsweise von der Erhebung von Daten bis hin zur automatisierten Ermittlung von Empfehlungen mit einem Verfahren des maschinellen Lernens erarbeiten (umfassende Erklärung des Empfehlungsdienstes sowie des ML-Verfahrens s.u.).
Im dritten Teil wird exemplarisch eine Zweitverwertung der Nutzungsdaten durch einen Streamingdienst thematisiert, indem eine Diskussionsrunde zu dem sekundären Zweck einer personalisierten Bezahlschranke basierend auf der Idee des Empfehlungsdienstes betrachtet wird. Dabei wird der Interaktionskontext hinsichtlich der Erhebung und Verarbeitung persönlicher Daten reflektiert und Handlungsoptionen insbesondere auf einer individuellen Betrachtungsebene bedacht und bewertet. In diesem Teil werden verschiedene Aspekte der Wechselwirkung zwischen Nutzendem und dem Streamingdienst (mit Fokus auf Empfehlungsdienste) thematisiert, wie etwa Verstärkungen von Abhängigkeiten im Nutzungsverhalten oder Wirkungen im Sinne der Idee von Filterblasen.
Im vierten Teil werden die gemachten Erfahrungen auf weitere mögliche Kontexte übertragen und so verallgemeinert, indem die Lernenden weitere datengetriebene Anwendungen aus ihrem Alltag untersuchen, in denen Empfehlungsdienste eingesetzt werden, wie zum Beispiel bei bestimmten Apps auf ihrem Handy. Im Rahmen einer Evaluation und Bewertung der Datenerhebung und -verarbeitung in den verschiedenen Beispielen können Vor- und Nachteile der Erhebung und Verarbeitung persönlicher Daten (z.B. Nutzungsdaten) diskutiert werden, um so den Lernenden eine Grundlage für reflektierten Entscheidungen hinsichtlich der Interaktion mit datengetriebenen Anwendungen dieser Art zu vermitteln.
Didaktische Kernidee: Förderung von Datenbewusstsein in diesem Unterrichtsmodul
Zur Umsetzung der Ziele und damit zum Fördern des Datenbewusstseins der Lernenden werden die Facetten von Datenbewusstsein in den vier Teilen des Unterrichtsmoduls umgesetzt. Das gewählte Beispiel im ersten Teil beschreibt ein Interaktionssystem bestehend aus einem Nutzendem und einem Streamingdienst bzw. dessen Empfehlungsdienst als datengetriebenes digitales Artefakt sowie der Interaktion zwischen diesen. Durch ein Spiel zu personalisierten Filmempfehlungen erarbeiten die Lernenden im ersten Teil die Bedeutung von personalisierten Filmempfehlungen und welche Rolle dabei Informationen bzw. Daten über die Person spielen. Dabei entwickeln sie Ideen für die explizite und implizite Erhebung von persönlichen Daten für den primären Zweck der Verwendung dieser Daten, des Ermittelns von personalisierten Filmempfehlungen. Diesen primären Zweck im Sinne der automatisierten Ermittlung von personalisierten Filmempfehlungen durch einen Empfehlungsdienst erarbeiten die Lernenden im zweiten Teil detaillierter. Dabei werden insbesondere auch die Konstruktion und Bedeutung des digitalen Doppelgängers eines Nutzenden hervorgehoben. Für einen sekundären Zweck der Verwendung und Verarbeitung der erhobenen Daten oder auch der digitalen Doppelgänger von Nutzenden wird im dritten Teil eine exemplarische, fiktive personalisierte Bezahlschranke thematisiert, in der verschiedene Aspekte der Wechselwirkungen in dem Interaktionssystem aufgegriffen werden. Dies veranlasst die Lernenden die Rolle der Daten und des Selbst in diesem exemplarischen Interaktionssystem zu reflektieren und die Erhebung und Verarbeitung von persönlichen Daten in einem solchen Interaktionssystem zu bewerten. Im vierten Teil werden die erlernten Kenntnisse zum Datenbewusstsein auf weitere Beispiele aus ihrem eigenen Alltag angewandt: Interaktion mit einem datengetriebenen digitalen Artefakt; explizite und implizite Datenerhebung; primäre und sekundäre Zwecke der Verwendung und Verarbeitung sowie Konstruktion eines digitalen Doppelgängers. Diese Kontexte werden anschließend reflektiert und kriteriengeleitet bewertet.
Ziele des Unterrichtsmoduls
In den vier Teilen des Unterrichtsmoduls werden im Wesentlichen folgende Ziele verfolgt:
- Teil 1: Filmempfehlungen und Datenerhebung durch einen Empfehlungsdienst
- Die Lernenden erkennen die Bedeutung von personalisierten Filmempfehlungen, indem sie exemplarisch anderen Lernenden in mehreren Schritten Filmempfehlungen geben und diesen Prozess der Verbesserung dieser Filmempfehlungen reflektieren.
- Die Lernenden unterscheiden die Begriffe der explizit und implizit erhobenen Daten und entwickeln Ideen dafür, welche Daten für die automatisierte Ermittlung von Filmempfehlungen explizit und implizit erhoben werden.
- Die Lernenden begründen exemplarisch die Notwendigkeit der expliziten und impliziten Erhebung von persönlichen Daten sowie deren Verarbeitung zum Ermitteln personalisierte Filmempfehlungen beispielhaft für die Erstellung einer Startseite bei einem Streamingdienst (primärer Zweck).
- Teil 2: Aufbau und Funktionsweise von Filmempfehlungsdiensten
- Die Lernenden erklären wesentliche Schritte zur automatisierten Ermittlung von personalisierten Filmempfehlungen basierend auf explizit und implizit erhobenen Daten (z.B. Nutzungsdaten), wobei sie auf die Grundidee des kollaborativen Filterns anhand des Verfahrens k-nearest-neighbors aus dem maschinellen Lernen eingehen.
- Die Lernenden beschreiben die Konstruktion eines digitalen Doppelgängers bei der Nutzung eines Streamingdienstes und begründen dessen Relevanz für einen Empfehlungsdienst.
- Teil 3: Zweitverwertung durch einen Empfehlungsdienst
- Die Lernenden erkennen den Vorschlag der Zweitverwertung für eine personalisierte Bezahlschranke als Idee für einen sekundären Zweck der Verwendung und Verarbeitung der erhobenen Daten bzw. des digitalen Doppelgängers, indem sie diese Idee aus verschiedenen Perspektiven in einer Diskussionsrunde (bzw. Rollenspiel) beleuchten.
- Die Lernenden erkennen mehrere Aspekte der Wechselwirkung zwischen Nutzendem und Streamingdienst, indem sie diese im Rahmen der Diskussionsrunde aufgreifen und bewerten.
- Die Lernenden beschreiben aus ihrer individuellen Perspektive Handlungsoptionen bzgl. der Interaktion mit einem Streamingdienst mit einem Empfehlungsdienst, indem sie eine Bewertung bzgl. der Erhebung und Verarbeitung von Daten im Rahmen der Interaktion mit einem Streamingdienst vornehmen und ein Fazit dazu formulieren.
- Teil 4: Weitere Kontexte mit Empfehlungsdiensten
- Die Lernenden wenden ihre gelernten Kenntnisse zum Datenbewusstsein auf weitere Beispiele eines datengetriebenen digitalen Artefakts aus ihrem Alltag an, indem sie an diesem Beispiel die explizite und implizite Datenerhebung, deren Verwendung und Verarbeitung zu primären und exemplarischen sekundären Zwecken sowie die Konstruktion von digitalen Doppelgängern identifizieren und beschreiben.
- Die Lernenden nehmen eine begründete Bewertung der Erhebung und Verarbeitung von Standortdaten in den thematisierten Beispielen vor, indem sie zum Beispiel auf den Kompromiss zwischen einem datensparsamen Verhalten und das Nutzen von individuellen oder gesellschaftlichen Vorteilen eingehen.
Leitfragen im Unterrichtsmodul
- Teil 1: Filmempfehlungen und Datenerhebung durch einen Empfehlungsdienst
- Was sind personalisierte Filmempfehlungen, welche Daten über Nutzende sind dafür hilfreich und welche kann ein Streamingdienst explizit und implizit erheben?
- Teil 2: Aufbau und Funktionsweise von Filmempfehlungsdiensten
- Wie können anhand von u.a. Bewertungsdaten (anhand explizit und implizit erhobener Daten) automatisiert personalisierte Filmempfehlungen ermittelt werden? (primärer Zweck)
- Wie wird ein digitaler Doppelgänger von einem Nutzenden konstruiert und welche Rolle spielt dieser für die Funktionsweise im Empfehlungsdienst?
- Teil 3: Zweitverwertung durch einen Empfehlungsdienst
- Wozu könnten persönliche Daten neben dem Zweck der Ermittlung personalisierter Filmempfehlungen ansonsten genutzt werden?
- Welche Bedeutung hat die Rolle der Daten im Rahmen der Nutzung von Streamingdiensten mit Empfehlungsdiensten hinsichtlich Aspekte der Wechselwirkung zwischen Nutzendem und dem Streamingdienst?
- Teil 4: Weitere Kontexte mit Empfehlungsdiensten
- In welchen anderen Kontexten werden Empfehlungsdienste eingesetzt, welche Daten werden dort erhoben und wozu werden sie verarbeitet?
- Welche Handlungsoptionen hat ein Nutzender in diesen Kontexten?
Zusammenfassender Überblick über das Unterrichtsmodul
Das Unterrichtsmodul mit den zentralen Aktivitäten, Leitfragen und Fachinhalten in den drei Teilen wird in der nachfolgenden Grafik zur Übersicht und Orientierung zusammengefasst.

Überblick über das Unterrichtsmodul
Hier wird zunächst eine grobe Reihenplanung mit den entsprechenden Materialien aufgeführt. Die Materialien, wie etwa Arbeitsblätter und ergänzende Informationen, der verschiedenen Phasen sind in der Tabelle hinterlegt. Eine detaillierte exemplarische Verlaufsplanung kann hier eingesehen werden: Verlaufsplan. Des Weiteren steht eine Handreichung mit ergänzenden Informationen für Lehrkräfte zur Verfügung, in der wir die verschiedenen Inhalte des Unterrichtsmoduls erläutern: Ergänzende Informationen
| Lerneinheit | Beschreibung der Lerneinheit | Materialien |
|---|---|---|
| 1 | Einstieg und Problematisierung:
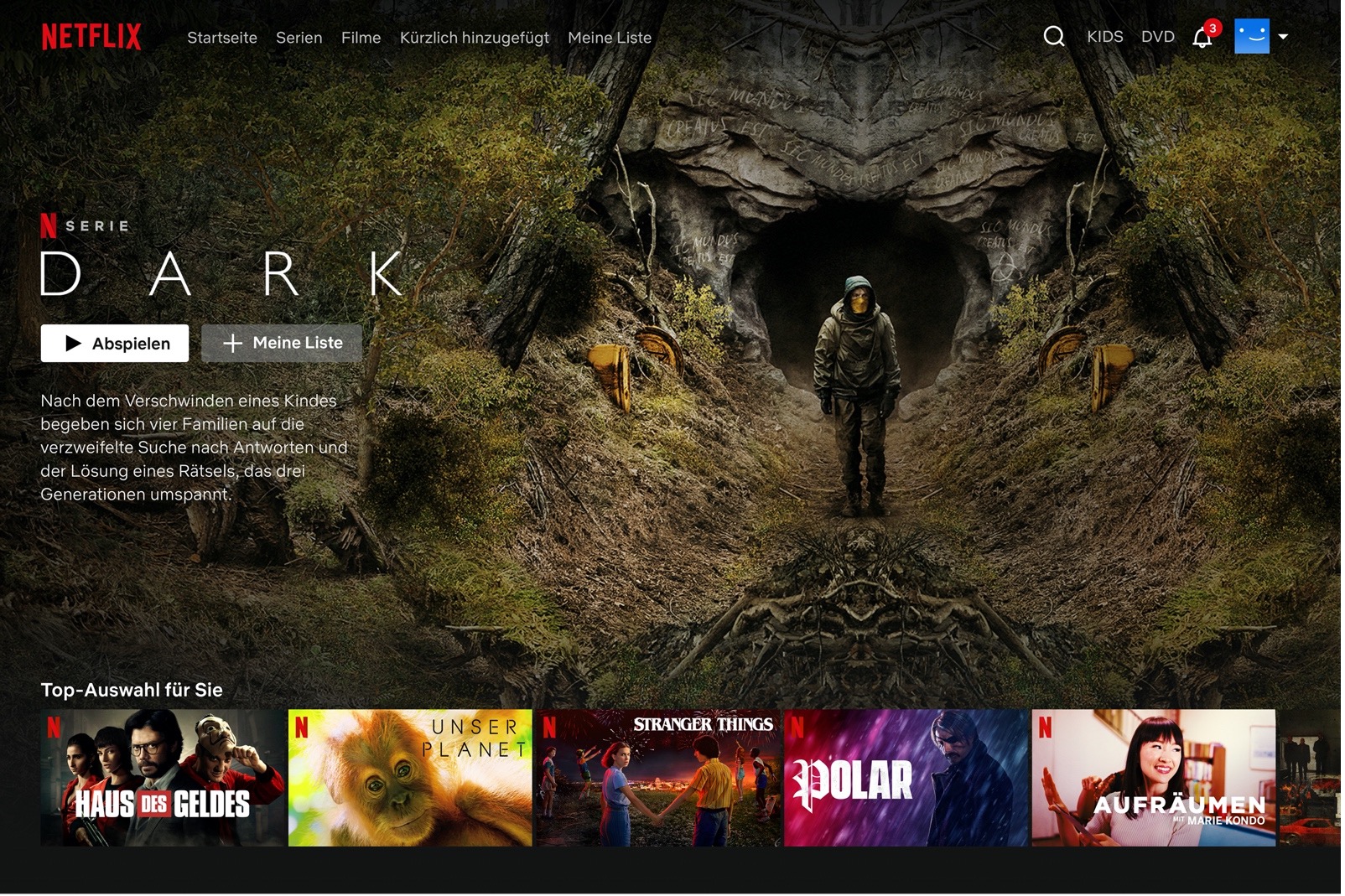
Die Lernenden bekommen ein Beispielbild einer Netflix-Startseite anhand derer sie erklären, was Streamingdienste sind. Gemeinsam wird hergeleitet, dass eine solche Startseite personalisiert ist, wodurch die Frage aufkommen sollte: Wie kommt eine personalisierte Startseite zustande und woher kommen diese Empfehlungen?
Idee: Was heißt „personalisierte Empfehlung/Werbung“? „Empfehlungsspiel“: Mit dem Spiel werden die Lernenden in das Ermitteln von Filmempfehlungen eingeführt. Dazu bearbeiten sie das AB1, wo sie sich gegenseitig Filmempfehlungen geben. Dabei wird erarbeitet, was personalisierte Filmempfehlungen sind und welche Informationen (bzw. Daten) dafür hilfreich sind. Damit soll die Rekonstruktion der expliziten und impliziten Erhebung von Daten durch einen Streamingdienst eingeleitet werden (Aufg. 4 auf AB1). Optional könnte zwischen Aufg. 3 und 4 eine Zwischensicherung eingelegt werden.
Reflexionsfragen: Welche Empfehlungen passten besser (Aufgabe 3)? Welche Fragen waren in Aufg. 2 hilfreich, welche eher weniger hilfreich? Hinführung zur Datenerhebung: Welche Informationen waren bei den Fragen hilfreich? Welche Daten könnten dann hilfreich sein, um Empfehlungen automatisiert zu ermitteln? (Daten vs. Information beachten)
|
Beispielbild einer Netflix-Startseite, Aussage: „Für alle Nutzer:innen existieren eigene personalisierte Startseiten, keine doppeln sich.“, ggf. Bild von Netflix-Sortierung, AB1 |
| 2 | Interaktion mit einem Empfehlungsdienst:
Die Lernenden bekommen ein Jupyter Notebook, in dem sie eigene Bewertungen von Filmen eingeben, anhand derer personalisierte Filmempfehlungen ermittelt werden. Anschließend untersuchen die Lernenden, welche Daten erhoben und verarbeitet werden und entwickeln Vermutungen zu Aspekten der Architektur dieses exemplarischen Empfehlungsdienstes. Dabei wird zwischen explizit und implizit erhobenen Daten unterschieden. |
Kapitel 1 im Jupyter Notebook (s.u.) |
| 3 | Rekonstruktion des Empfehlungsdienstes („Maschinenraumbetreten“):
Die Lernenden erkunden in mehreren Aufgaben die explizit und implizit erhobenen Daten – diese werden als Datentabellen ausgegeben – und rekonstruieren die Verarbeitung zum primären Zweck der Auswahl von anzuzeigenden Filmen und zum sekundären Zweck des verbessern des Nutzungserlebnisses (Steigerung des Profits durch mehr Interaktionszeit mit dem Streamingdienst). Dabei können sie bei der Bearbeitung zwischen den explizit und implizit erhobenen Daten wählen. Leitfragen für die Rekonstruktion:
Die Rekonstruktion im Jupyter Notebook wird durch mehrere Zwischensicherungen begleitet.
Es sollte festgehalten werden, welchen persönlichen Daten vorliegen und wie damit personalisierte Empfehlungen ermittelt werden können (z.B. Prozess der Ermittlung festhalten). Es sollte auch besprochen werden, dass die implizit erhobenen Daten sehr hilfreich sein können und allein damit bereits gut personalisierte Empfehlungen ermittelt werden können. |
Kapitel 2 im Jupyter Notebook (s.u.), AB2 |
| 4 | Reflexion der Zweitverwertung der Daten (sekundärer Zweck) - Rollenspiel:
Die Lernenden diskutieren ein vorgeschlagenes Geschäftsmodell in einem Rollenspiel:
|
AB3a, AB3b |
| 5 | Reflexion weiterer ähnlicher Interaktionskontexte:
Die Lernenden sammeln ähnlicher Interaktionskontexte aus dem Alltag, in denen Empfehlungsdienste vorkommen. Anschließend wählen die Lernenden in Kleingruppen ein Beispiel aus und rekonstruieren mit dem AB4 die explizit und implizit erhobenen Daten sowie entwickeln Ideen für primäre und sekundäre Zwecke der Verwendung und Verarbeitung der Daten. Nachdem die verschiedenen Gruppenergebnisse vorgestellt und diskutiert wurden, bewerten die Lernenden abschließend Empfehlungsdienste in ihrem Alltag, wobei sie sich auf eine individuelle und auf eine gesellschaftliche Ebene beziehen sollen. |
{kind=link}
Beschreibungen ausgewählter Materialien
Das vorbereitete Jupyter Notebook
(Verlinkung folgt noch - bei Interesse gerne an Lukas Höper der Universität Paderborn wenden)